标题:WebClipper源码解析——让你轻松保存网页内容的神器
摘要:本文将详细介绍WebClipper的原理和源码结构,带你深入了解这款网页内容保存神器的工作原理与技术细节。
引言:
WebClipper是一款用于保存网页片段的浏览器插件,它可以帮助你快速、简洁地保存页面中有价值的信息,以便日后查阅和整理。那么它的运作原理是什么,又是如何实现这些功能的呢?接下来,让我们从源码的角度揭开WebClipper的神秘面纱。
一、WebClipper原理简介
WebClipper的核心原理是通过JavaScript将HTML文档或特定DOM节点捕获为图像保存到客户端,同时还具备OCR(Optical Character Recognition,光学字符识别)功能,将图片中的文字识别为可编辑文本。
为实现这些功能,WebClipper会用到以下几个关键技术:
1. 跨域请求:跨域请求是指页面加载来自于不同域名(如 b.com)的资源 (如a.com上的图片),实现:通过CORS(跨域资源共享)解决请求
2. 画布(canvas):用于绘制所需保存的特定区域内的内容,实现截屏功能
3. DOM解析:处理HTML文档,识别特定区域内的文字、图片等元素,并进行处理。
4. 数据URL(DataURL):将数据通过Base64编码后,以DataURL形式呈现,方便将图片等元素存储。
5. OCR技术:将图片中的文字识别为可编辑文本。
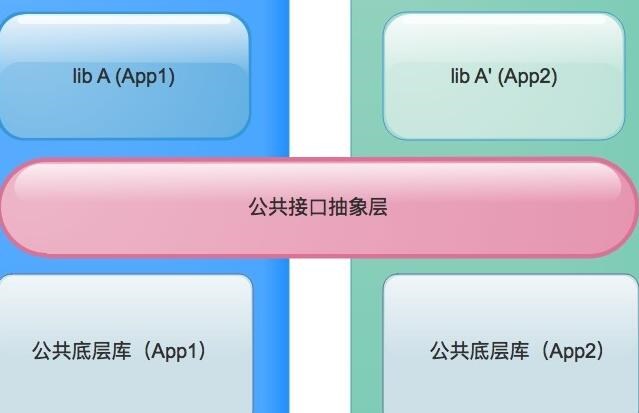
二、WebClipper源码结构与解析
接下来我们进行进一步的源码解析。假设我们对常见的WebClipper插件如:"Evernote Web Clipper"或"Microsoft OneNote Web Clipper"进行分析。
1. 背景脚本(background script)
背景脚本是插件的核心部分,负责响应用户与插件之间的交互。主要功能包括监听插件激活事件、刷新页面、添加右键菜单等。典型的背景脚本文件如 background.js。
2. 页面脚本(content script)
用于实现浏览器和实际页面的交互。content script会来加载HTML和CSS到当前的文档,并处理跨域请求。典型文件例如content.js。
3. 页面UI
包括HTML、CSS和JS等。用户可以通过使用主要通过HTML渲染的弹出窗口操作WebClipper进行保存页面片段等功能。对于Evernote WebClipper,可以查看clip.html、clipper.css和clipper.js文件。
4. 函数库
WebClipper会用到很多基础函数库,如jQuery、vue等。这些库会用来保证交互的流畅、兼容性等。
三、实现逻辑
接下来我们简要介绍WebClipper的实现逻辑。
1. 用户通过点击浏览器插件,触发background.js中监听的激活事件。
2. background.js将通过向当前页面发送消息,通知content.js加载所需资源。
3. 用户通过弹出窗口选择保存的区域,content.js会根据选择生成所需截屏的区域。
4. 利用canvas绘制选定区域的内容,并将绘制结果生成DataURL格式的图片。
5. 如果需要OCR功能,将DataURL格式的图片传递给OCR API,获取文字结果。
6. 最后将结果保存到Evernote、OneNote等服务端,或者直接保存到本地。
总结:
通过对WebClipper源码的分析,我们了解到了它的核心原理、技术栈以及整个实现过程。作为一款网页内容保存神器,它的工作原理简洁而高效。希望本文的介绍能够帮助大家更好地理解WebClipper的实现原理,并在实际应用中做到得心应手。